
Primero que todo configuramos para nuestro renovado server una de las instancias con mejor performance de memoria según Amazon las instancias R3 [0]
Las instancias R3 están optimizadas para aplicaciones con un uso intenso de la memoria y ofrecen el coste más bajo por GiB de RAM entre los tipos de instancias de Amazon EC2.Estos servidores tienen un Almacenamiento de Instancia [1] respaldado en Disco SSD pero estos son temporales por consiguiente si se Para y luego se Inicia nuevamente todo lo que habia en ese disco simplemente desaparece. Por eso decidimos seguir respaldando la DB en un EBS [2] y para mejorar un poco más la performance decidimos poner dos EBSs en RAID0
Entonces empecemos contando que es un EBS. Amazon Dice:
Amazon Elastic Block Store (Amazon EBS) proporciona volúmenes de almacenamiento de nivel de bloque persistentes y diseñados para utilizarlos con las instancias de Amazon EC2 en la nube de AWS.En resumen son digamos unos discos rigidos a pedido que van y vienen por la nube y que se pueden adjuntar a cualquier tipo de Instancia de EC2 y que son de almacenamiento permanente.
Ahora vamos con un poco sobre algo que siempre me costó entender ¿que es un RAID? [3]. Básicamente es un conjunto de discos independientes que se usan en conjunto generalmente para dar mayor redudancia a las implementaciones de Almacenamiento. Releyendo para escribir este Post me acuerdo cual es el motivo de que nunca lo terminara de entender y el motivo es que tiene muchos niveles y algunos resultan realmente complejos. Nivel se le llama a cada tipo de configuración que existente. Obviamente nosotros vamos a explicar algunas de las más caracteristicas.
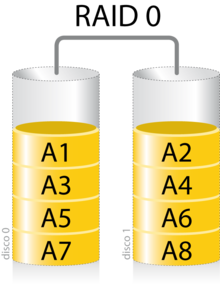
El RAID0 (Data Striping) es la útilización de un conjunto de discos fisicos como si fueran uno solo. En verdad lo que se hace es distribuir equitativamente los datos en uno y otro disco por lo que esta configuración no le agrega redundancia al almacenamiento pero si nos ayudará en la mejora del rendimiento de lectura y escritura. En cuanto al tamaño este es limitado por el más pequeño de los discos si se tiene 2 discos de 100 GB el tamaño se duplicaría entonces pasariamos a tener un disco de 200GB ya que cada uno aporta 100GB a la distribución, pero si se tiene un disco de 300GB y uno de 100GB la distribución se hace sobre el más pequeño y cada uno aporta 100GB por lo que se obtiene un disco de 200GB perdiendo 200GB del disco más grande.
El RAID1 (Mirroring) crea una copia exacta de cada dato que va a un disco en uno o más. Esto es bueno para entornos donde es más importante la velocidad de lectura que la capacidad ya que (en su implementación más básica) se usarían dos discos de 100 GB cada uno y el máximo de almacenamiento es tanto como el más pequeño de los discos. Además tener un disco copiado exactamente le agrega redundancia al conjunto lo que es muy útil en ambientes de alta disponibilidad ya que si un disco falla el otro puede tomar su lugar sin demasiado problema.

Hay más? Si mucho más y es un tema largo y se puede volver bastante complejo. Leer en Wikipedia te va a dar una buena mirada [3].
Ahora vamos a lo nuestro como configurar un RAID0 para una instancia EC2 sobre Volúmenes EBS primero adjuntamos dos volumenes EBS a nuestra Instancia esto se puede hacer durante el lanzamiento de la Instancia en la Sección de "Add Storage" o posteriormente desde el Panel de Volúmenes de EC2 creando un Volumen y luego adjuntandolo a la Instancia. En este caso vamos a usar dos volúmenes de 30 GB.
Nosotros somos gente grosa así que usamos el tipo de servidores que sostiene al 95% de Internet servidores Linux entonces vamos a usar el comando "lsblk" que según man "lista los dispositivos de bloque"
vamos a ver algo como esto
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 8G 0 disk
└─sda1 8:7 0 8G 0 part /
sdb 8:0 0 30G 0 disk
sdc 8:0 0 30G 0 disk
El disco sda de 8G es el que se monta como root por default en todas las intancias EC2 y el sdb y sdc son los que se van a usar para hacer el RAID0.
$ sudo mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=numero_de_volumenes dispositivo_1 dispositivo_2
Ejemplo:
$ sudo mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 sdb sdc
Esto básicamente lo que hace es crear un nuevo dispositivo llamado md0 con los bloques sdb y sdc usando el nivel "stripe" que también podría ser "0" o "raid0"
-l, --level=
Set RAID level. When used with --create, options are: linear,
raid0, 0, stripe, raid1, 1, mirror, raid4, 4, raid5, 5, raid6,
6, raid10, 10, multipath, mp, faulty, container. Obviously some
of these are synonymous.
Luego crearemos un sistema de archivos y un punto de montaje para montar el dispositivo.
$ sudo mkfs.ext4 /dev/md0
$ sudo mkdir /mnt/md0
$ sudo mount -t ext4 /dev/md0 /mnt/md0
Una vez montado ya podremos usarlo pero tendremos algunos problemas (no aparecerá el punto de montaje) si paramos y prendemos la instancia para eso se debe agregar la siguiente linea al archivo /etc/fstab.
/dev/md0 /mnt/md0 ext4 defaults 0 0
Como dice el man de fstab
The file fstab contains descriptive information about the various file systems. fstab is only read by programs, and not written; it is the duty of the system administrator to properly create and maintain this file.
Y listo ya tenemos nuestro raid0 configurado en nuestra instancia ec2 o en verdad en cualquier linux.
Pueden probar como mejora el performance de IO con diferentes herramientas hdparm [4] o bonnie++ [5]
Más data de como hacer esta configuración y sus ventajas y desventajas en el siguiente link [6]
[0] http://aws.amazon.com/es/ec2/instance-types/
[1] http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/InstanceStorage.html
[2] http://aws.amazon.com/es/ebs/
[3] http://es.wikipedia.org/wiki/RAID
[4] http://es.wikipedia.org/wiki/Hdparm
[5] http://en.wikipedia.org/wiki/Bonnie++
[6] http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/raid-config.html
